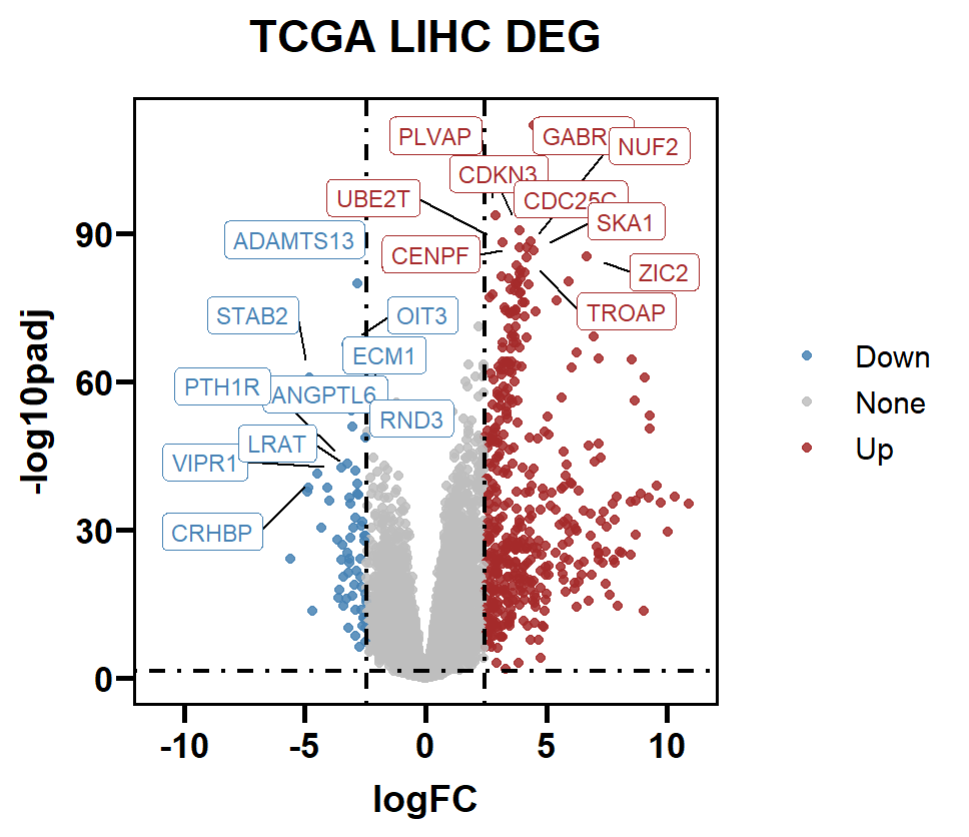
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
| ### 解压数据,创建存储文件夹----
# 我们使用命令行下载的,直接就是解压后的文件目录,可以跳过这一步
# setwd("TCGA-LIHC") # 设置工作路径
# dir.create('RawMatrix/') # 新建文件夹存储下载的原始数据
# tar_file <- "./gdc_download_20241222_135942.082516.tar.gz"
# extract_dir <- "./RawMatrix"
# untar(tar_file, exdir = extract_dir) # 导入tar.gz,并解压文件
#数据准备----
# C:/Users/Administrator/project_gdc2/RawMatrix 是数据目录
rm(list = ls()) #### 魔幻操作,一键清空~
getwd()
setwd('C:/Users/Administrator/project_gdc2')
dir.create('RawData/') # 新建文件夹存储count/TPM/差异表达矩阵等txt格式
dir.create('RawData/csv/') # 新建文件夹存储csv格式的矩阵
### 数据整理----
library(data.table)
library(dplyr)
sample_sheet <- fread("./gdc_sample_sheet.2024-12-22.tsv") # 读取样本信息
sample_sheet$Barcode <- substr(sample_sheet$`Sample ID`,1,15) # 取ID前15字符作为barcode
sample_sheet1 <- sample_sheet %>% filter(!duplicated(sample_sheet$Barcode)) # 去重
sample_sheet2 <- sample_sheet1 %>% filter(grepl("01$|11$|06$",sample_sheet1$Barcode))
# table(as.numeric(substr(sample_sheet1$Barcode,14,15) < 10) == 1)
# 0 1
# 50 373
# sample_sheet1$Barcode[!grepl("01$|11$|06$",sample_sheet1$Barcode)]
# [1] "TCGA-DD-AACA-02" "TCGA-ZS-A9CF-02"
# 02是可以用的,也是肿瘤样本。直接用sample_sheet1。
# 发现02的同时也有01样本,所以是要移除后使用。
# Barcode的最后两位:01表示肿瘤样本,11表示正常样本,06表示转移样本
# A:Vial, 在一系列患者组织中的顺序,绝大多数样本该位置编码都是A; 很少数的是B,表示福尔马林固定石蜡包埋组织,已被证明用于测序分析的效果不佳,所以不建议使用-01B的样本数据:
# 02也是要的
TCGA_LIHC_Exp <- fread("./RawMatrix/0036fcec-eaed-430b-9a23-5efb2d2cc7f2/32b682ec-8156-44ca-bff0-26155c7fdc12.rna_seq.augmented_star_gene_counts.tsv") # 任意读取一个文件
# 创建包含"gene_id","gene_name","gene_type"的数据框,用于合并表达数据
TCGA_LIHC_Exp <- TCGA_LIHC_Exp[!1:4,c("gene_id","gene_name","gene_type")]
### 将所有样本合并成一个数据框
for (i in 1:nrow(sample_sheet2)) {
folder_name <- sample_sheet2$`File ID`[i]
file_name <- sample_sheet2$`File Name`[i]
sample_name <- sample_sheet2$Barcode[i]
data1 <- fread(paste0("./RawMatrix/",folder_name,"/",file_name))
#unstranded代表count值;如果要保存TPM,则改为 tpm_unstranded
data2 <- data1[!1:4,c("gene_id","gene_name","gene_type","tpm_unstranded")]
colnames(data2)[4] <- sample_name
TCGA_LIHC_Exp <- inner_join(TCGA_LIHC_Exp,data2)
}
### 根据需要的表达比例筛选满足条件的基因
zero_percentage <- rowMeans(TCGA_LIHC_Exp[, 4:ncol(TCGA_LIHC_Exp)] == 0)
TCGA_LIHC_Exp1 <- TCGA_LIHC_Exp[zero_percentage < 0.6, ] # 筛选出超过60%样本中存在表达的基因
#28842
TCGA_LIHC_Exp1 = avereps(TCGA_LIHC_Exp[,-c(1:3)],ID = TCGA_LIHC_Exp$gene_name) # 对重复基因名取平均表达量,并将基因名作为行名
TCGA_LIHC_Exp1 <- TCGA_LIHC_Exp1[rowMeans(TCGA_LIHC_Exp1)>100,] # 根据需要去除低表达基因,这里设置的平均表达量100为阈值
dim(TCGA_LIHC_Exp1)#13526
### 创建样本分组
library(stringr)
tumor <- colnames(TCGA_LIHC_Exp1)[substr(colnames(TCGA_LIHC_Exp1),14,15) == "01"]
normal <- colnames(TCGA_LIHC_Exp1)[substr(colnames(TCGA_LIHC_Exp1),14,15) == "11"]
tumor_sample <- TCGA_LIHC_Exp1[,tumor]
normal_sample <- TCGA_LIHC_Exp1[,normal]
exprSet_by_group <- cbind(tumor_sample,normal_sample)
dim(exprSet_by_group)
gene_name <- rownames(exprSet_by_group)
exprSet <- cbind(gene_name, exprSet_by_group) # 将gene_name列设置为数据框的行名,合并后又添加一列基因名
### 存储counts和TPM数据
# fwrite(exprSet,"./RawData/TCGA_LIHC_Count.txt") # txt格式
# write.csv(exprSet, "./RawData/csv/TCGA_LIHC_Count.csv", row.names = FALSE) # csv格式
fwrite(exprSet,"./RawData/TCGA_LIHC_Tpm.txt") # txt格式
write.csv(exprSet, "./RawData/csv/TCGA_LIHC_Tpm.csv", row.names = FALSE) # csv格式
|