AI使用滚动时间序列交叉验法评估模型
编辑
2
2025-06-27

提示词
# Python代码
# 使用slearn中的线性回归创建模型
from sklearn.linear_model import LinearRegression
# 使用前一天的收盘价作为自变量,预测当前天的收盘价
# 将收盘价向后移动一天,作为预测值
df['Next_Close'] = df['收盘价'].shift(-1)
# 选择自变量(前一天的收盘价)
X = df[['收盘价']].iloc[:-2] # 除了最后两个数据作为 X
# 选择因变量(下一天的收盘价)
y = df['Next_Close'].dropna().iloc[:-1] # 除了最后一个数据作为 y
# 创建并拟合线性回归模型
model = LinearRegression()
model.fit(X, y)
# 预测下一个时间点的收盘价
next_day_close = model.predict(df[['收盘价']].iloc[[-2]]) # 用倒数第2天的数据预测
print("预测的下一个时间点的收盘价:", next_day_close)
# 预测训练集数据
predicted_close = model.predict(X)
# 可视化真实值与预测值
plt.figure(dpi=300)
plt.plot(df.index[:-2], y, label='实际收盘价',
color='r',lw=0.5) # 真实值
plt.plot(df.index[:-2], predicted_close,
label='预测收盘价',ls='--',lw=0.5) # 预测值
plt.xlabel('Date')
plt.ylabel('收盘价')
plt.title('真实值对比预测值')
plt.legend()
plt.savefig('图7-1.jpg', dpi=300)
plt.show()
继续使用上面的黄金期货行情数据,需要使用前一日的收盘价作为自变量,下一日的收盘价作为因变量创建线性回归模型,并使用滚动时间序列交叉验证法对模型的性能进行评估,最后将真实值与模型预测值进行可视化,请给出示例代码。
答案
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 假设df是包含日期索引和'收盘价'列的DataFrame
# 创建目标变量:下一日收盘价
df['Next_Close'] = df['收盘价'].shift(-1)
df = df.dropna() # 删除最后一行NaN
# 设置滚动窗口大小(250个交易日≈1年)
WINDOW_SIZE = 250
# 初始化存储预测结果的列表
predictions = []
actuals = []
dates = []
# 滚动时间序列交叉验证
for i in range(WINDOW_SIZE, len(df)):
# 获取训练数据(窗口内的前WINDOW_SIZE个点)
X_train = df['收盘价'].iloc[i-WINDOW_SIZE:i-1].values.reshape(-1, 1) # 前一日收盘价
y_train = df['Next_Close'].iloc[i-WINDOW_SIZE:i-1] # 当日收盘价
# 获取测试数据(窗口外的下一个点)
X_test = df['收盘价'].iloc[i-1].reshape(1, -1) # 最后一天的收盘价
y_test = df['Next_Close'].iloc[i] # 要预测的下一天收盘价
# 创建并训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测下一个时间点的收盘价
pred = model.predict(X_test)[0]
# 存储结果
predictions.append(pred)
actuals.append(y_test)
dates.append(df.index[i]) # 预测对应的日期
# 转换为DataFrame便于处理
results = pd.DataFrame({
'Date': dates,
'Actual': actuals,
'Predicted': predictions
}).set_index('Date')
# 计算评估指标
mse = mean_squared_error(results['Actual'], results['Predicted'])
rmse = np.sqrt(mse)
mae = mean_absolute_error(results['Actual'], results['Predicted'])
r2 = r2_score(results['Actual'], results['Predicted'])
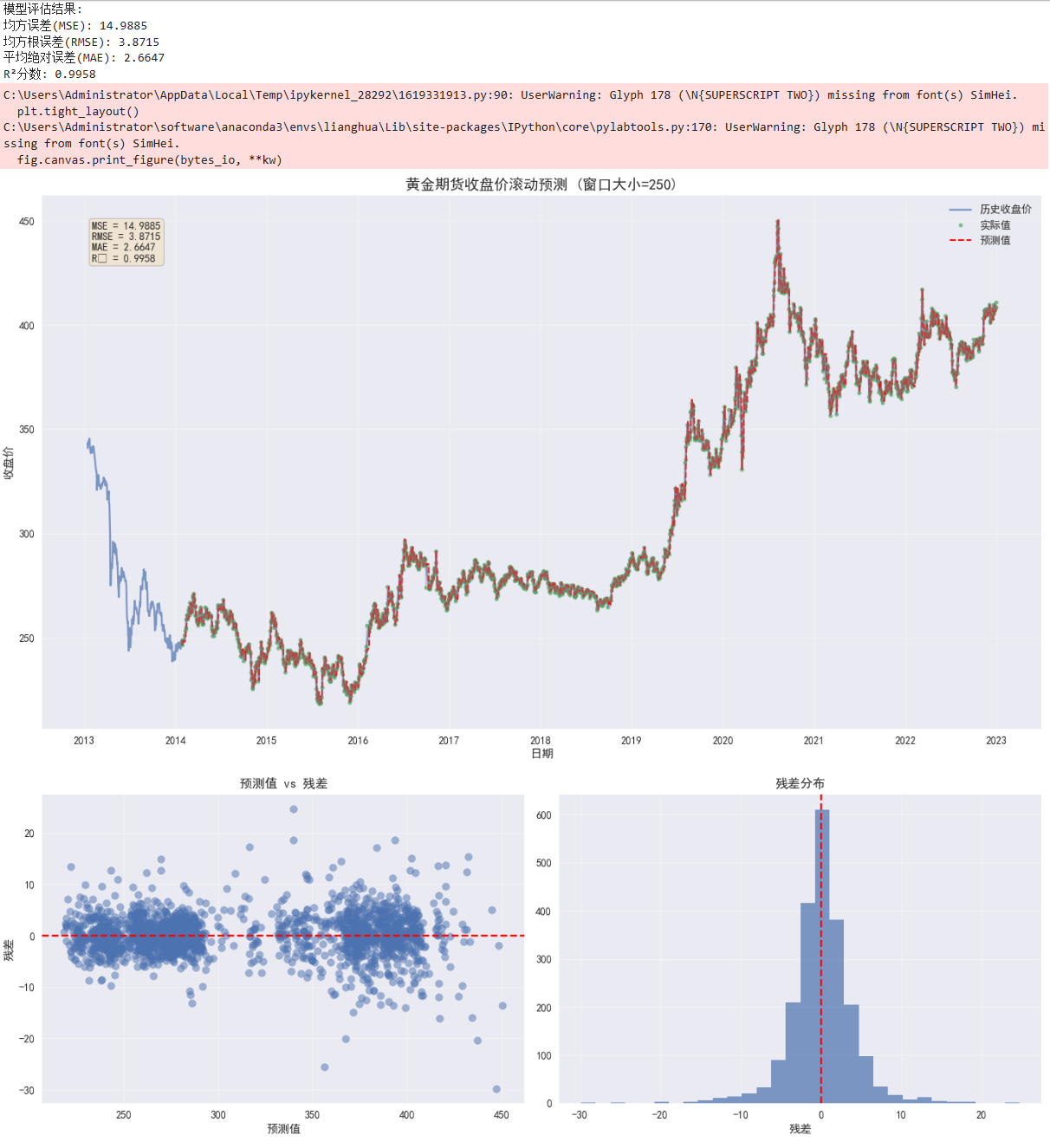
print(f"模型评估结果:")
print(f"均方误差(MSE): {mse:.4f}")
print(f"均方根误差(RMSE): {rmse:.4f}")
print(f"平均绝对误差(MAE): {mae:.4f}")
print(f"R²分数: {r2:.4f}")
# 可视化结果
plt.figure(figsize=(14, 8))
plt.plot(df['收盘价'], label='历史收盘价', alpha=0.7)
plt.plot(results.index, results['Actual'], 'o', label='实际值', markersize=4, alpha=0.7)
plt.plot(results.index, results['Predicted'], 'r--', label='预测值', linewidth=1.5)
# 添加预测误差线
for i, date in enumerate(results.index):
plt.plot([date, date],
[results['Actual'].iloc[i], results['Predicted'].iloc[i]],
'gray', alpha=0.3)
# 添加图例和标题
plt.title(f'黄金期货收盘价滚动预测 (窗口大小={WINDOW_SIZE})', fontsize=14)
plt.xlabel('日期')
plt.ylabel('收盘价')
plt.legend()
plt.grid(alpha=0.3)
# 添加评估指标文本框
textstr = '\n'.join((
f'MSE = {mse:.4f}',
f'RMSE = {rmse:.4f}',
f'MAE = {mae:.4f}',
f'R² = {r2:.4f}'))
props = dict(boxstyle='round', facecolor='wheat', alpha=0.5)
plt.gca().text(0.05, 0.95, textstr, transform=plt.gca().transAxes,
fontsize=10, verticalalignment='top', bbox=props)
plt.tight_layout()
plt.show()
# 残差分析
residuals = results['Actual'] - results['Predicted']
plt.figure(figsize=(14, 5))
plt.subplot(1, 2, 1)
plt.scatter(results['Predicted'], residuals, alpha=0.5)
plt.axhline(y=0, color='r', linestyle='--')
plt.title('预测值 vs 残差')
plt.xlabel('预测值')
plt.ylabel('残差')
plt.grid(alpha=0.3)
plt.subplot(1, 2, 2)
plt.hist(residuals, bins=30, alpha=0.7)
plt.title('残差分布')
plt.xlabel('残差')
plt.axvline(x=0, color='r', linestyle='--')
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
我发现选择用了固定250窗口移动来训练,预测右侧窗口外的第一个数据,而我本意是拆分不同窗口的训练和测试集合,看起来ai的这种计算量大一点。
图像:
- 0
- 0
-
赞助
 支付宝
支付宝
 微信
微信
-
分享